Human emotions are complex. And it is more complicated when people are trying to put them in words. Then, there are sarcasm and satire. Without knowing the context or the person, it is difficult to label a text as a positive or negative sentiment.
Today, I am going to work on Sentiment Analysis using TextBlob. I will extract the data from Twitter for #Racism and #alllivesmatter hashtags.
In some of my previous posts, I have worked on scraping data from twitter and on some basic Text Analysis. Below are a few of them:
- Collect Tweets From Twitter
- Streaming Tweets from Twitter
- Explore Twitter Trends By Location
- Text Analytics on #coronavirus
Today, I will try to read the sentiment behind a Tweet. Let’s divide the sentiment into 3 broad categories:
- Positive
- Negative
- Neutral
Usually, when we work on Sentiment Analysis and we have some Rating and Feedback/Reviews text, the analysis seems easier. On a scale of 1-5, a 1 or 2 usually represents Negative, a 3 means Neutral, and a 4 or 5 means positive. With a poor Rating, it is unlikely to praise the product or add positive reviews, right? So, if we are analyzing the Amazon or Yelp reviews along with a Rating, there are different algorithms to build a Model.
But, analyzing Twitter Text is an example of Unsupervised Learning. We can only work on classifying the text in some categories. Now, I will use the TextBlob library to process the textual data. TextBlob is a common Natural Language Processing tool that can be used for part-of-speech tagging, noun phrase extraction, sentiment analysis, and more.
So, let the work fun begin!
Import Libraries
We will import the required libraries first.
##Import Libraries
import tweepy
#
import sys
import config
##Preprocessing
import pandas as pd
import re
from langdetect import detect
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
st = PorterStemmer()
from nltk.tokenize import word_tokenize
from textblob import Word
from textblob import TextBlob
set(stopwords.words('english'))
from wordcloud import WordCloud
##Plot
import matplotlib.pyplot as plt
import seaborn as sns
##To sort dictionary values
import operator
Initialize Twitter API
I have stored my consumer key and secret code information in a config file and accessing it here without displaying the details.
##initialize api instance consumer_key= config.consumer_key consumer_secret= config.consumer_secret access_token=config.access_token access_token_secret =config.access_token_secret
Connect to Twitter
Now, let’s connect to Twitter using Tweepy Library.
##Connect to Twitter through the API auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth,wait_on_rate_limit=True)
Create Function to collect Tweets
The below function will fetch Tweets for some keywords. I have filtered out the re-tweets. Even tough I am working only on the text part i.e. the tweets with hashtags like #alllivesmatter and #racism, I am collecting some other information like user name, screen name, location etc.
Function Call
Now, let’s call the above function and collect 1000 tweets for each hashtag.
if name == 'main': ##Setting up the keywords, hashtag keywords = ['#Racism','#alllivesmatter'] ##Call Function to collect tweets df_tweets = getTweets(keywords,1000)
Explore Data
We have got a Dataframe with the below columns:
- Screen_Name
- User_Name
- Location
- Keyword
- Text
df_tweets.info()
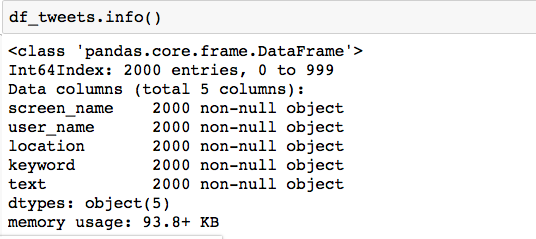
df_tweets.head()

Data Preprocessing
We need to clean the Twitter Text before any further analysis. So, we can work on some basic cleanup like removing the URLS, the punctuation marks, spaces, numbers and stop words, etc. After the cleanup, we will add a new column as clean text in the same data frame.
##convert to lower case
df_tweets['clean_text'] = df_tweets['text'].str.lower()
##Remove punctuations
df_tweets['clean_text'] = df_tweets['clean_text'].str.replace('[^\w\s]',' ')
##Remove spaces in between words
df_tweets['clean_text'] = df_tweets['clean_text'].str.replace(' +', ' ')
##Remove Numbers
df_tweets['clean_text'] = df_tweets['clean_text'].str.replace('\d+', '')
##Remove trailing spaces
df_tweets['clean_text'] = df_tweets['clean_text'].str.strip()
##Remove URLS
df_tweets['clean_text'] = df_tweets['clean_text'].apply(lambda x: re.split('https:\/\/.*', str(x))[0])
##Remove stop words
stop = stopwords.words('english')
stop.extend(["racism","alllivesmatter","amp","https","co","like"])
df_tweets['clean_text'] = df_tweets['clean_text'].apply(lambda x: " ".join(x for x in x.split() if x not in stop ))
##Remove Text Column
#del df_tweets['text']
Create a Wordcloud
I have created a wordcloud in all of my previous text analytics posts. It seems like I am kind of obsessed with them. It is simple and speaks a volume.
word_cloud = WordCloud(width = 800, height = 800, background_color ='white',max_words = 1000)
word_cloud.generate_from_frequencies(data)
##plot the WordCloud image
plt.figure(figsize = (10, 8), edgecolor = 'k')
plt.imshow(word_cloud,interpolation = 'bilinear')
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
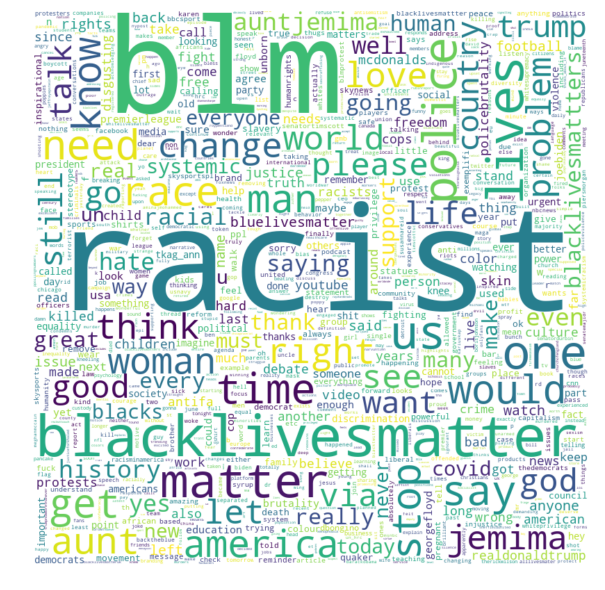
Sentiment Analysis
This is the most important part of this post. I wanted to try my hands on TextBlob. TextBlob Sentiment returns a tuple of the form (polarity, subjectivity ) where polarity ranges in between [-1.0, 1.0], and subjectivity is a float within the range [0.0, 1.0] where 0.0 is very objective and 1.0 is very subjective. Now, I am using only the polarity to get a score. Based on the Sentiment Score, I am dividing Sentiments into 3 broad categories.
df_tweets['sentiment_score'] = [round(TextBlob(text).sentiment.polarity, 3)for text in df_tweets['clean_text']]
df_tweets['sentiment_category']
= ['positive' if score > 0
else 'negative' if score < 0
else 'neutral'
for score in df_tweets['sentiment_score']]
Visualization
Finally, let’s take a quick look at how the data looks like at this point.

Now, let’s plot the sentiment_category column and take a look at which sentiment is ruling today.
fc = sns.factorplot(x="sentiment_category", hue="sentiment_category",
data=df_tweets, kind="count",
palette={"negative": "#FE2020",
"positive": "#BADD07",
"neutral": "#68BFF5"})
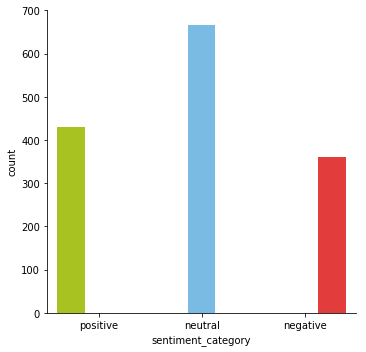
It looks like most people are demonstrating “Neutral” Sentiments on Twitter when talking about #Racism or #Alllivesmatter. I am not a political person. And that’s why I can comment based on data and not being judgemental. Still, I would really like to know what a Positive Sentiment looks like when it comes to #Racism.
df_tweets[df_tweets['sentiment_category'] == 'positive'][["screen_name","user_name","text"]]
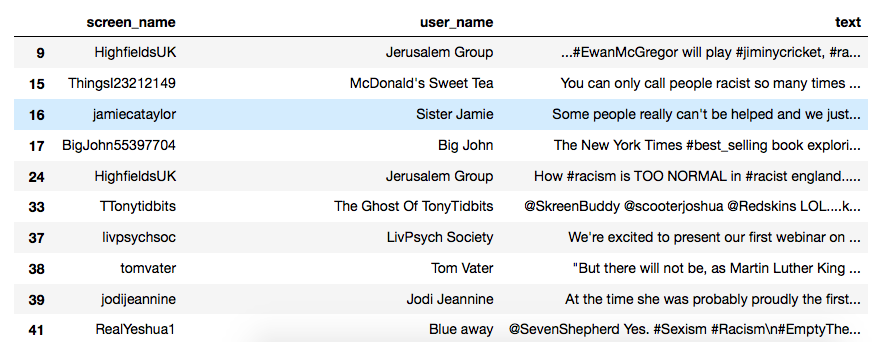
Let’s take a look at the one of this tweets in twitter.

Well, can we tag this as a positive sentiment? So, how does a negative sentiment look like?
df_tweets[df_tweets['sentiment_category'] == 'negative'][["screen_name","user_name","text"]]

Now, if I have to put a tag here, I would call this as a Neutral. Am I tagging it all wrong? Maybe based on polarity, we can not classify this broadly? Let’s take a look at a wordcloud with only negative sentiments.
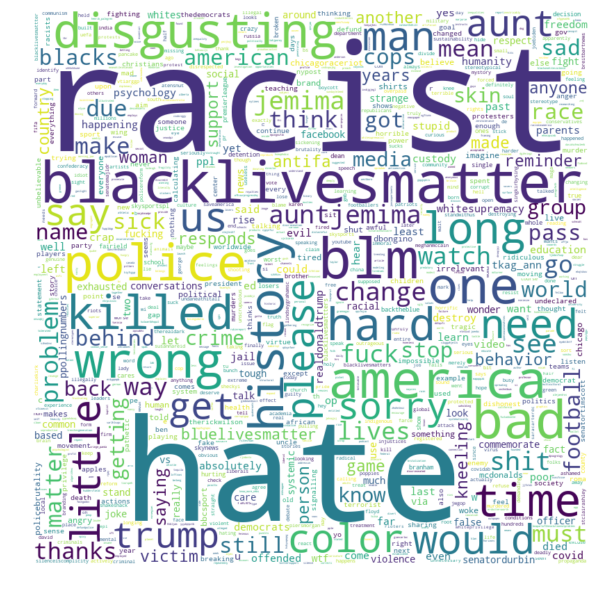
Well, that looks appropriate right? What do you think?
I still do believe that human sentiments are too knotty and tricky to tag. But, we can try to put a broad label on a text data and that way, TextBlob did a fantastic job!
The Jupyter Notebook for this project is in my Github. Please take a look if any of the above code is not working for you.
Let’s keep Tweeting, keep Analyzing and keep growing our insights!
Thank You!
2
Niloy Sengupta
This is really a great initiative. What would be further interesting are :
1. If you could correlate the findings and check that if those who tweet racist rants also tweet in favor of Trump, against marriage equality, for gun rights, against climate change and so on (the so called Conservative issues)
2. What percentage of Twitter users, who are otherwise progressive, are also racists?
Premanka
Nice initiatives