I was trying to read a CSV file in Python using the below command and got an error.
Error: UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xe6 in position 11: invalid continuation byte
import pandas as pd
df = pd.read_csv("users.csv")
What is UnicodeDecodeError?
Python uses “utf-8” as the default Unicode encoding on Mac OS X. This can be confirmed by the below commands:
import sys
sys.getfilesystemencoding()
sys.getdefaultencoding()
Both of the above commands resulted in “utf-8” on Mac OS X.
Well, still something was missing. I want a direct answer as to why I am getting the above error and what is the solution. Finally, I got my answers.
My users file as some names like “ÿstergaard Dennis” and ÿ is an invalid byte sequence in utf-8.
Try below command:
str(b'xff', 'utf8')
This will raise the same UnicodeDecodeError.

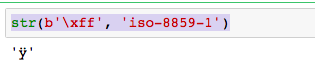
Now, Try the below command:
str(b'xff', 'iso-8859-1')
The same byte sequence is valid in another charset like ISO-8859-1.
This leads to the solution!
df_users = pd.read_csv("takehome_users.csv",encoding = "ISO-8859-1")
The above command worked perfectly and my data is loaded.