What is Scraping?
Web Scraping is a technique for fetching and then extracting information from websites. Every website hosts information over the web in the form of HTML or some static text and scraping involve taking in HTML code and extracting relevant information like the title of the page, headings in the page, links or email address, etc.
What is Goodreads?
Goodreads is a social cataloging website that allows individuals to freely search for books and reviews. Users can sign up and generate library catalogs and reading lists or can create their own groups of book suggestions.
How do we do Scraping?
Manual scraping: Manually copying and pasting the web page content
Text Pattern Matching: Using the UNIX grep command
Google Docs: From Google sheets, using the IMPORTXML(, ) function
HTML parsing: Using some programming (JAVA, PYTHON, etc.) scripts
How do we scrape Goodreads using Python?
Now, that is the question that this post is all about!
We use Web Scraping to extract some information from a website. Goodreads actually provide an API to get that information. But, in this post, I will extract information using the old style, using some Python Libraries.
So, let’s start scraping!
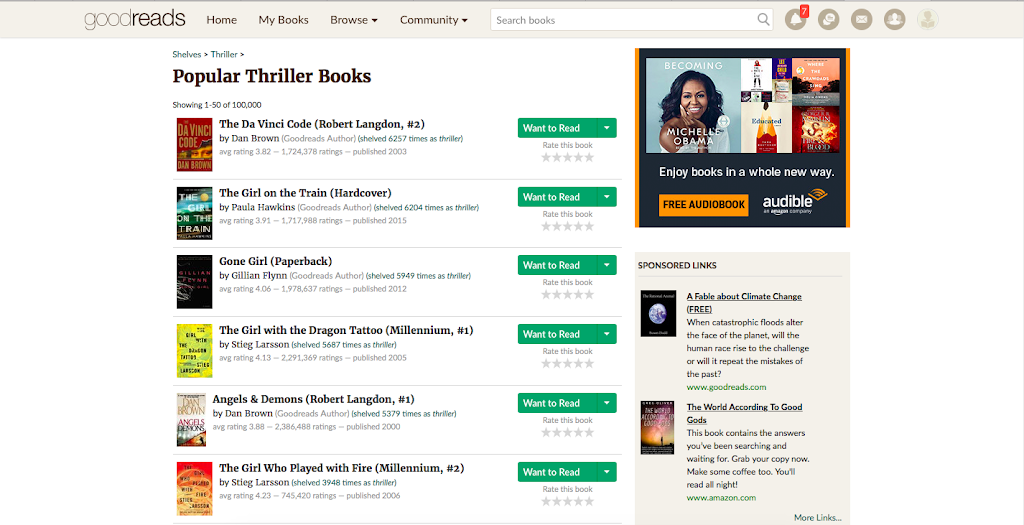
In this Post, I will scrape the below page – “Thriller Shelf” from Goodreads.
URL = https://www.goodreads.com/shelf/show/thriller
2. BeautifulSoup for web scraping
pip install requests pip install bs4
Let’s first import the above libraries and let the fun begin!
import requests from bs4 import BeautifulSoup as bs
Now, since we have all the libraries required, let’s start cooking.
url= "https://www.goodreads.com/shelf/show/thriller" page = requests.get(url) soup = bs(page.content, 'html.parser') print(soup)
Thus, here goes the soup containing all the Information I need:
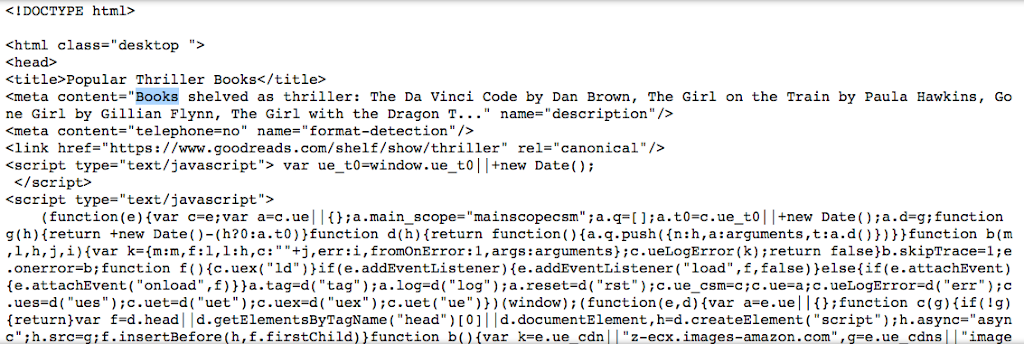
The next thing is to extract the important Data out of this soup.
We will extract 2 details:
1. Book Title
2. Author Name
titles = soup.find_all('a', class_='bookTitle')
authors = soup.find_all('a', class_='authorName')
print(titles)
At this point, the Title and the Author data is still not the way I was looking for! But, we are almost there.

for title, author in zip(titles, authors):
print("Book: ", title.get_text(), "By: " , author.get_text())
And BOOM! Here goes the output that we were looking for! We have the Book Title and the corresponding Author!

Unknown
python online Evantatech provides you the best python online training with practical oriented course with the help of real time faculty.