As the story goes, I was going through the Neural Network Exercise from the Andrew Ng Course of Machine Learning. I converted the .mat file to a .csv file long back. The steps are mentioned in another post here.
But then, it took me some time and lots of effort to finally start practicing the digit recognition problem in R. Before starting my hands on Neural Networks, I wanted to try some other classification algorithms and check the accuracy. In my previous post, I used a Decision Tree for this Classification Problem.
In this post, I will try the randomForest Algorithm.

The first few steps are the same as in my last post and thus copy-pasted from before.
So, Let’s divide the whole process into the below steps:
1. Load Data
2. Divide Data into Training and Test Set
3. Exploratory Data Analysis
4. Create a Model
5. Prediction
1. Load Data:
I have used the Dataset from “machine-learning-ex4” from Andrew Ng ‘s Machine Learning Course. I converted the .mat files to a .csv files. Let’s load the data first and take a look.
Now, let’s see what we are doing in the above piece of code.
- Load 2 data files:We have 2 data files. The first data file has 5000 training examples, where each training example is a 20 * 20 (400) pixel grayscale image of a digit. Thus, each pixel is represented by a floating-point number indicating the grayscale intensity at that location. The 20 by 20 grid of pixels is “unrolled” into a 400-dimensional vector. The second data file is a 5000-dimensional vector y that contains labels for the training set.
- Merge the 2 Datafiles: I have loaded both the datasets and merged them into a single file. Let’s check the dimension of each file.

- Rename the “output” column: The output file column name is “V1”. Also, the pixel value dataset has a column named “V1”. So, I renamed the output file column to “Output” to avoid any confusion.
- Convert Output to a Factor column: If we check the class of the “Output” Column, it is “Integer”. Let’s Convert it to a Factor Column with 10 levels.
- Check if any column has Missing Value: I just wanted to check if there is any missing value. But it seems like there is not missing value and we are all set for the next step.
2. Divide Data into Training and Test Set:
At this step, we will divide the dataset into the Training and Test set. We will use 70% of the data for training our Model and the other 30% to test the accuracy of our Model.
3. Exploratory Data Analysis:
This is a fun and colorful part. Let’s plot!
It’s time to find out how our Training Set looks like.

Hmm, all the digits are almost equally distributed in the Training Dataset. Now, we will see how the handwritten Digits in our training set looks like. We have created a function for the same and passed a few records randomly and below is the output.

4. Create a Model:
We will use the Random Forest for this classification problem. We are going to use the library randomForest for the same. Let’s build a Model!
It took some time to build the Model with ntree = 100.

Okay, now let’s take a peek at the plots.

It looks like the error is gradually getting stable after 60 trees are iterated.
5. Prediction:
This is the most fun part. We will use the test dataset and this Random Forest Model and check how accurate is the prediction.
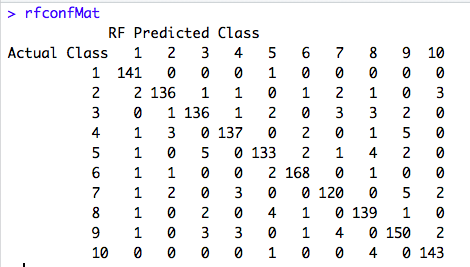
The Confusion Matrix shows the match is better with this Model than my Decision Tree Model, build earlier. Accuracy is 0.9353333333. Now, that’s a good number!

Also, the 182nd record is also predicted correctly, this time. Then I generated a random number and used that number to check the actual output and predicted output.

Yay! It matches every time I tried.
So, this randomForest Model is definitely a better fit!
Below are the other Algorithms used for digit recognition in R:
- Hand-Written Digit Recognition in R using Multinomial Logistic Regression
- Hand-Written Digit Recognition in R using Neuralnet
- Hand-Written Digit Recognition in R using rpart
Thank You!