
Problem:
Create our first WordCloud using R
Solution:
For Text Mining, one useful library is “tm”. To stem text, we will use the library “SnowballC” and to create the worcloud, we will use the library “WordCloud”.
Now, we will go deeper. But first, let’s install all these libraries.
install.packages("tm")
install.packages("SnowballC")
install.packages("wordcloud")
Now, let’s divide the whole process into the below steps:
1. Load Data Files:
The dataset is comprised of tab-separated files with phrases from the Rotten Tomatoes dataset.
Each phrase has a PhraseId.
Each sentence has a SentenceId.
- train.tsv contains the phrases and their associated sentiment labels.
- test.tsv contains just phrases.
For this post, we will load the training dataset alone and will create a word cloud.

There are 156060 observations and 4 variables. The reviews are stored in the “Phrase” variable. In this post, we will work with this variable alone.
2. Data Preprocessing:
2.1. Create a Corpus
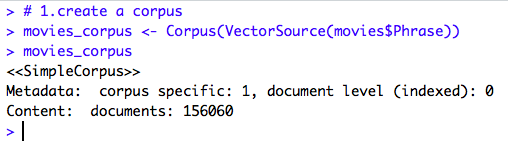
Now, let’s take a look at the first review, and then finally we will see what transformation we have done.

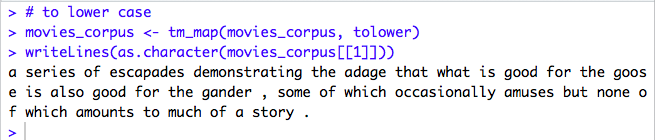
2.2. Convert all text To Lowercase
The corpus is then run through a series of tm_map functions. getTrasformations() function lists the predefined mappings that can be used with tm_map().

“tolower” will convert the text to lower case. Otherwise, the wordcloud might highlight capitalized words separately. So, the first alphabet “A” is converted to lowercase “a”.
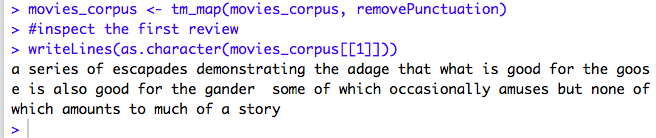
2.3. Remove Punctuations
Since we are dealing with the Text here, we can remove all the punctuations by using the argument removePunctuation. It removes punctuation (periods, commas, hyphens, apostrophes etc. ). The comma(,) before some and the stop (.) at the end is removed.
2.4. Remove Stop Words
Stopwords are the commonly used words in the English language such as I, me, my, etc. We can see the full list of stopwords using stopwords(‘english’).

We need to pass removeWords and the stopwords(“english”) to remove the most commonly used words and below isthe result.

2.5. Remove Numbers:
removeNumbers will remove the numerical number i.e. 1(and not one) in case there are any numbers in the text since numbers are not that useful to create a wordcloud. Our first movie review has no numbers in this example.
2.6. Remove the White Space:
Now, after removing some words and punctuations, some white spaces are created in between which we can remove bypassing the argument stripWhitespace.

2.7. stemDocument
stemDocument is supposed to convert all the words to their stem i.e. if there are two words like “walking” and “walked”, stemDocument is supposed to convert them to the root word “walk”. “tm” library also has a predefined transformation “stemDocument”. “SnowballC” library is also a useful library for stemming. But honestly, I do not understand this completely and I am not happy with the result. I need to dig in more into this stemDocument concept. But for the time being, let’s create our first word cloud.

3. Create Document Term Matrix:
Document matrix is a table containing the frequency of the words. Column names are words and row names are documents. The function “TermDocumentMatrix()” or “DocumentTermMatrix()” from “tm” package can be used as follow :

A matrix is created with all the words and the number of times each of them being used in the documents. If we check the summary of the “freq” variable, we could see each word is being used at least once and the maximum frequency is 7787!

4. Create a WordCloud:
Finally, the most awaited step – To create a word cloud with the frequently used or the most important words. Function wordcloud() from the library “wordcloud” is used here.
If we just pass the arguments words and freq, in the function wordcloud(), a black and white word cloud would be created as below:
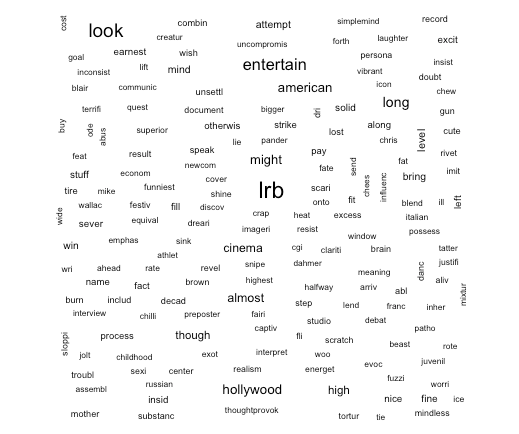
Now, let’s add a few more arguments and create a colorful word cloud:
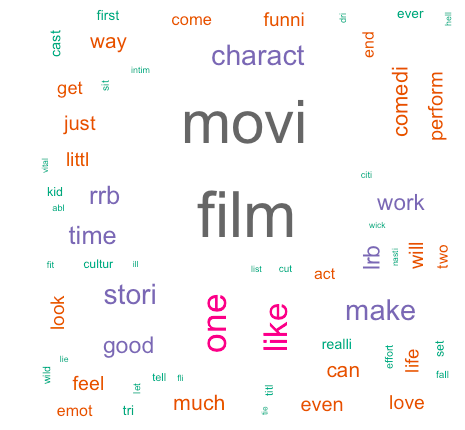
Some of the important Arguments for the function wordcloud() is as below:

Charles
Thank you so much for this nice information. Hope so many people will get aware of this and useful as well. And please keep update like this.
Text Analytics Software
Data Scraping Tools
Charles
Thank you so much for this nice information. Hope so many people will get aware of this and useful as well. And please keep update like this.
Text Analytics Companies
Sentiment Analysis Tool