
I was browsing the competitions in Kaggle with Category as “Getting Started” and the one that caught my attention is “Bag of Words Meets Bags of Popcorn“. This competition is about Sentiment Analysis in Machine Learning. Well, that is super interesting! In Kaggle, there is a tutorial in Python. Since I am still struggling with R, I thought of checking out and understand the concepts of Text Analytics in R first.
What is my understanding of Text Analytics/Text Mining?
There is a wide collection of Text Data in this world. When we are writing a review about a product in Amazon, or a restaurant in Yelp or about a Hotel in TripAdvisor, we are putting our sentiments in words. These words contain a lot of information. Text Analytics is the process to read these large text data and to derive some meaningful insights.
For a human Being, it is both time and cost consuming to analyze all the Text and Predict or find a pattern. That’s why we train Computers to analyze Text. This field of study is called “Natural Language Processing“. But again, it is difficult for the computer to understand and predict some useful information from some text because a person can use Metaphors, Sarcasm, Wrong Spellings, or some non-traditional grammar or any natural language to express their sentiments.
Text Analytics Workflow:
1. Define the problem and set some distinct goals
2. Collect the Text to analyze
4. Build a Text Analytics Model
5. Start Analysis and reach an insight
Text Analytics applications:
I use the Amazon App a lot and it is amazing. I was looking for a Knee Support and was looking for Customer Reviews. Reading a review is so easy and see how the most used words are separated. That’s so cool, right?
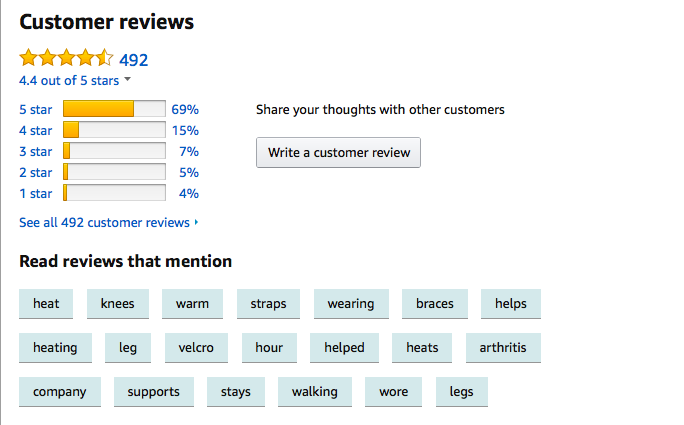
The number of Stars can be misleading sometimes. One customer can give 3 stars and still happy with the product and another customer can give 3 stars and write some genuine problems in the review. So, to get the actual picture, reading the text is so important.
Some other real-life scenarios where Text Analytics are used are as follows:
- Sentiment Analysis e.g if a Tweet about a company is positive or negative.
- Text Classification e.g classifying the emails we get as spam or ham.
- Text Clustering e.g. Automatic labeling of documents by topics in business libraries
- Entity extraction e.g identifying people, places, organizations, and other entities from documents.
- Document summarization i.e. to automatically provide the most important points in the original document. This is particularly good for news summary.
In R, the package tm provides a Text Mining Framework. There are a lot of other packages which are used in Natural Language Processing and the list is here.
So, let’s start our Text Analytics journey and have some fun!
0
Charles
Thank you so much for this nice information. Hope so many people will get aware of this and useful as well. And please keep update like this.
Text Analytics Companies
Sentiment Analysis Tool