Dplyr() is the data manipulation package in R and is described in detail here.
Problem:
Use of Dplyr Summarise() in R
Solution:
Summarise() reduces multiple values down to a single summary.
Example:
For this example, we can use the data sets related to flights that departed from NYC in 2013.
We have installed the dataset in our previous post and you can get the code here.
We have installed the dataset in our previous post and you can get the code here.
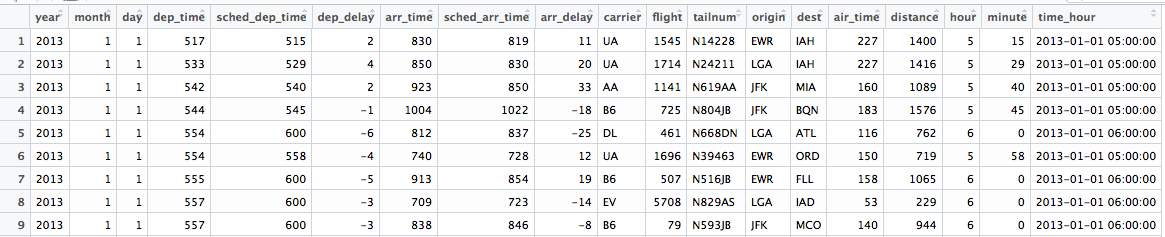 |
| Flights |
Summary Functions in R:
|
min(), max()
|
Minimum and Maximum Values
|
|
mean()
|
Mean Value
|
|
median()
|
Median Value
|
|
sum()
|
Sum Of Values
|
|
var(), sd()
|
Variance and Standard Deviation of a Vector
|
|
first()
|
First Value in a Vector
|
|
last()
|
Last Value in a Vector
|
|
nth()
|
Nth Value in a Vector
|
|
n()
|
The Number of Values in a Vector
|
|
n_distinct
|
The Number of distinct Values in a Vector
|
Summarise() Code:
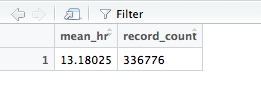 |
| Flight_mean_hour |
 |
| Flight_dist_origin |
Thank You!